有时候我们经常会在文献中看到许多图表,特别是一些表示两个变量关系的散点图,但作者往往不一定提供原始数据,我们当然可以想办法联系作者获取原始数据,但有时候这样不但成功率不高,而且像一些早年的文献,可能作者无法联系,甚至原始数据已经无法获得了。
那么有什么办法么?今天看到Wu Lingfei写了一个文章,讲“摄影法”求原始数据,说白了就是拍(或扫描)一张无透视的图片,稍加处理便可得到其相对准确的原始数据。我在这里改良了一下原始方法,发挥建院同学的优势,可以前期用PS辅助处理一下,以增加准确度。
STEP 1:拍照
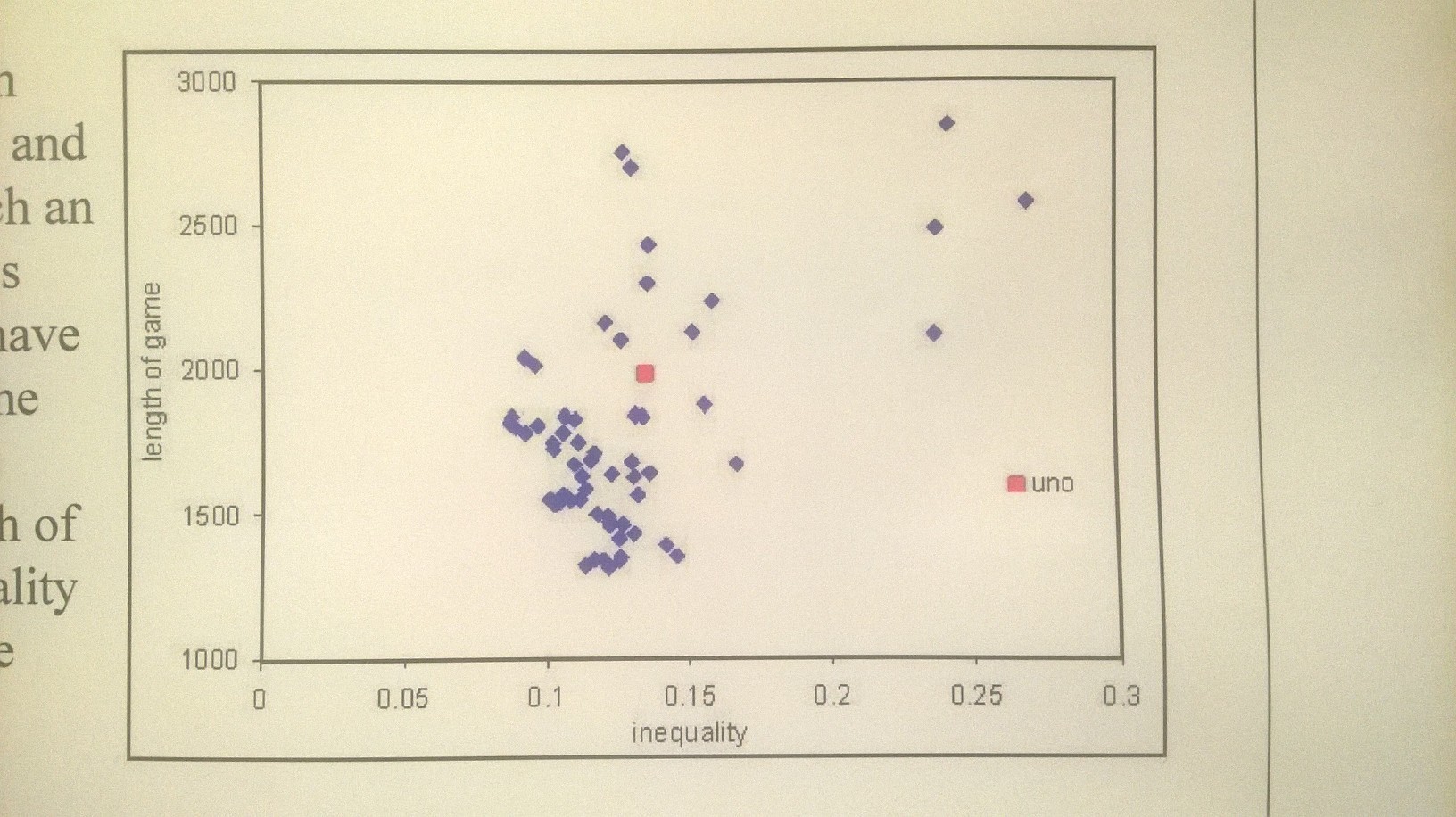
这是原文作者用手机拍的一张照片,虽然说手机也可以有不错的拍照效果,但难免会有透视,而且数据点清晰度低的话可能会影响后一步处理,如果可能的话建立试试扫描仪。
STEP 2:预处理

将图片在PS里先剪裁一下,大小需要正好剪裁到坐标轴边框;接着调整成阈值模式,再进一步其实可以单独用画笔点一下数据点,因为“粘连”在一起的数据点到后面计算机是没法分开的。
下面的工作就交给计算机啦。
STEP 3:用Python的包识别出点的组团
# -*- coding: utf-8 -*-
import numpy as np #数组
import matplotlib.pyplot as plt #画图
from scipy import ndimage #核心!图片处理
from scipy.ndimage import measurements
j = ndimage.imread("/Users/mac/Desktop/figure1.jpg")
#j是一个y行,x列的array
b = ndimage.gaussian_filter(j,4)
#用高斯法处理图片,得到点的cluster
c,d = ndimage.label(b<50)
#给cluster打上标签,后面b的值是个阈值,可调节
im = plt.imshow(c)
plt.show()
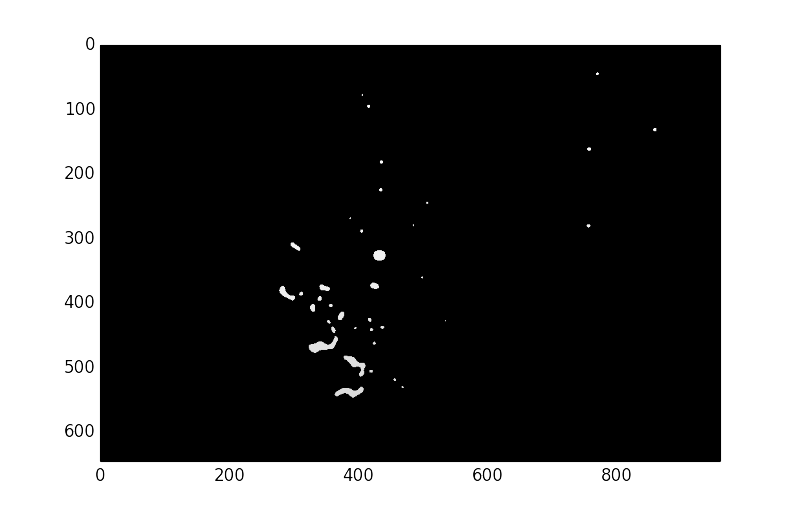
STEP 4:画出所有Cluster,并存下中心点的数据
# -*- coding: utf-8 -*-
import numpy as np #数组
import matplotlib.pyplot as plt #画图
from scipy import ndimage #核心!图片处理
from scipy.ndimage import measurements
j = ndimage.imread("/Users/mac/Desktop/figure1.jpg")
#j是一个y行,x列的array
b = ndimage.gaussian_filter(j,4)
#用高斯法处理图片,得到点的cluster
c,d = ndimage.label(b<50)
#给cluster打上标签,后面b的值是个阈值,可调节
sliced = measurements.find_objects(c)
#Find objects in a labeled array. Find points in this example
data=[]
for i in sliced:
sliceX = i[1]
sliceY = i[0]
#注意,X,Y的坐标是反的
x = np.abs(sliceX.stop - sliceX.start)/2 + min(sliceX.stop,sliceX.start) #point center x
y = np.abs(sliceY.stop - sliceY.start)/2 + min(sliceY.stop,sliceY.start) #point center y
xlim = [0,len(j[0])]
ylim = [len(j),0]
data.append([x,ylim[0]-y]) #换一下y的坐标
plt.plot([sliceX.start, sliceX.start, sliceX.stop, sliceX.stop, sliceX.start], \
[sliceY.start, sliceY.stop, sliceY.stop, sliceY.start, sliceY.start], \
color="c")
plt.xlim(xlim)
plt.ylim(ylim)
plt.imshow(c)
plt.show()
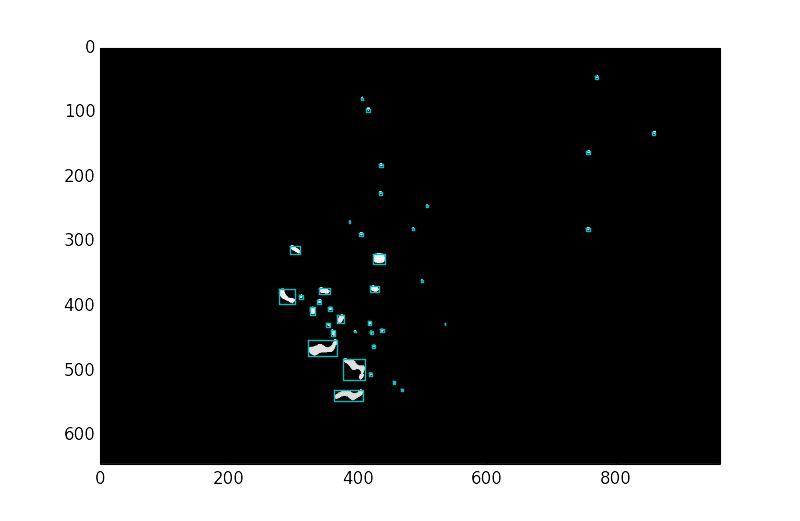
STEP 5:对数据结合原坐标轴进行变换,得到真实数据
# -*- coding: utf-8 -*-
import numpy as np #数组
import matplotlib.pyplot as plt #画图
from scipy import ndimage #核心!图片处理
from scipy.ndimage import measurements
j = ndimage.imread("/Users/mac/Desktop/figure1.jpg")
#j是一个y行,x列的array
b = ndimage.gaussian_filter(j,4)
#用高斯法处理图片,得到点的cluster
c,d = ndimage.label(b<50)
#给cluster打上标签,后面b的值是个阈值,可调节
sliced = measurements.find_objects(c)
#Find objects in a labeled array. Find points in this example
data=[]
for i in sliced:
sliceX = i[1]
sliceY = i[0]
#注意,X,Y的坐标是反的
x = np.abs(sliceX.stop - sliceX.start)/2 + min(sliceX.stop,sliceX.start) #point center x
y = np.abs(sliceY.stop - sliceY.start)/2 + min(sliceY.stop,sliceY.start) #point center y
xlim = [0,len(j[0])]
ylim = [len(j),0]
data.append([x,ylim[0]-y]) #换一下y的坐标
plt.plot([sliceX.start, sliceX.start, sliceX.stop, sliceX.stop, sliceX.start], \
[sliceY.start, sliceY.stop, sliceY.stop, sliceY.start, sliceY.start], \
color="c")
xlim_org = [0,0.3]
ylim_org = [1000,3000]
x = []
y = []
#xlim_org,ylim_org是图片上的坐标轴,x,y用来存点的x坐标和y坐标
for k in range(len(data)):
data[k][0] *= (0.3/len(j[0]))
data[k][1] = data[k][1] * 2000/len(j) + 1000
x.append(data[k][0])
y.append(data[k][1])
plt.xlim(xlim_org)
plt.ylim(ylim_org)
plt.scatter(x, y ,c='blue', s=50, alpha=0.8)
plt.show()
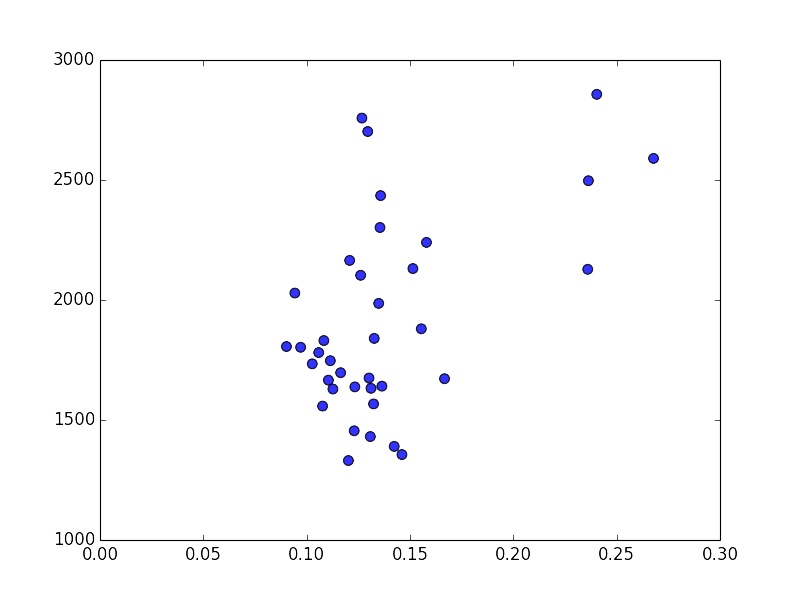
是不是很像呢?data这个list里存的就是点的真实坐标了,因为有些Cluster这种简单的方法识别还是不太好,可以进一步处理,点不多的情况下也可以在之前PS的时候调整好。