上篇文章提到了一些有趣的图形,再之前一篇文章讲了用R导入地图的问题。如果把数据和地图结合可以展现更多有意思的结论。这里我们就说说与地图有关的数据可视化,所有素材都来自上文提到的Visualize This一书,但书出版后有些软件版本进行了更新,用原书中的代码会报错,所以我修订了新的代码。
准备工作:
1、软件安装。本文涉及Python及其插件BeautifulSoup(版本为4);R及其插件maps(在R中装插件很容易,只需要输入install.packages(maps)就行)。
2、数据。美国一家商店在美国开店的数据,世界范围内国家生育率的数据,美国失业率的数据。后文会给出链接。
3、底图。一张美国的SVG底图,可以在这里下到。
第一张图:
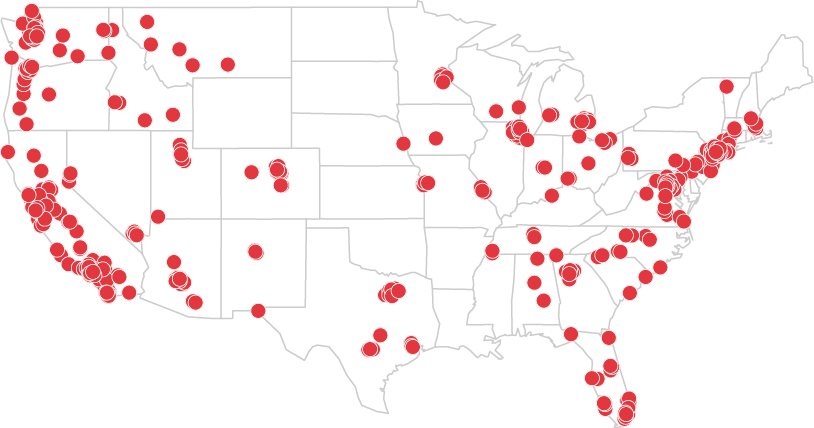
这是一家连锁店全美开店位置图。可以看到它主要集中在东西海岸,数据在这里下载。
library(maps) #载入maps
costcos <- read.csv("http://book.flowingdata.com/ch08/geocode/costcos-geocoded.csv", sep = ",") #载入数据
map(database = "state", col = "#cccccc") #载入美国地图,底图设为灰色
symbols(costcos$Longitude, costcos$Latitude, bg = "#e2373f", fg = "#ffffff",
lwd = 0.5, circles = rep(1, length(costcos$Longitude)),
inches = 0.05, add = TRUE)
#add=TRUE表示在上张图上叠加symbols;前两个变量代表横纵坐标;bg是填充颜色,fg是框线颜色;lwd是线的粗度;circles是圆,后面的括号代表一个数组,长度为地图上点的数量;inches表示圆的大小
第二张:
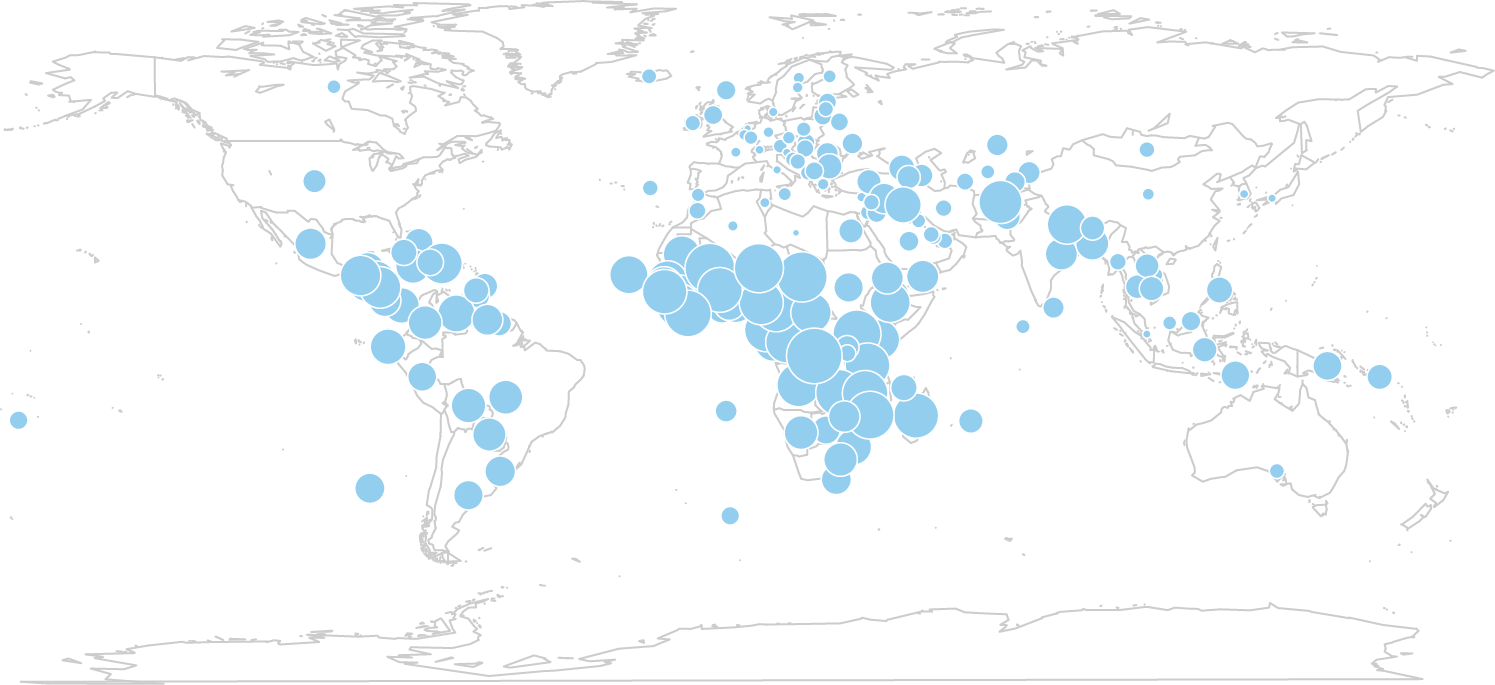
第二张图是《2008年联合国人类发展报告》中未成年人生育率(每1000名15-19岁女性中生育数量)。数据可以在这里下载。
library(maps) #载入maps
fertility <- read.csv("http://book.flowingdata.com/ch08/points/adol-fertility.csv")
map('world', fill = FALSE, col = "#cccccc") #选择世界地图,不填充,底图为灰色
symbols(fertility$longitude, fertility$latitude,
circles = sqrt(fertility$ad_fert_rate), add = TRUE,
inches = 0.1, bg = "#93ceef", fg = "#ffffff") #圆圈的大小(面积而非半径)由生育率决定
第三张:
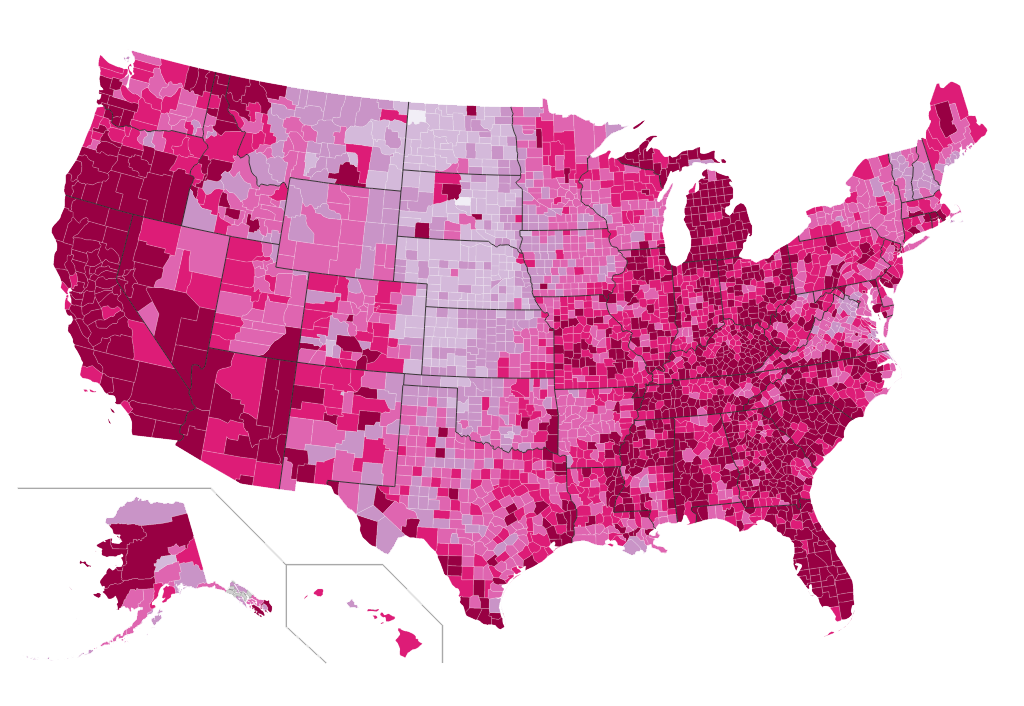
这是美国2010年8月失业情况按县域的分布,红色越深表示失业率越高,下次我记得加比例尺。数据可以在这里下载。和文章一开始提到的地图放到一个文件夹下。
这张图比前两张复杂不少,其于Python而不是R完成,思路就是找到地图中不同区域,然后让数据中表示的区域与地图表示的一一对就,再用失业率分成几种颜色向对应区域填充,主要分为三步:
- 载入数据和地图,这里SVG地图是矢量地图,可用文本编辑,这也是可用Python处理的基础。
- 用各自的“地址”对应区域,需要将失业率数据中的地址做些小处理以和SVG图中的匹配。
- 填充颜色,这组颜色由ColorBrewer生成,其实可以选择任何自己喜欢又能表达充分的色系。
具体代码如下,注意BeautifulSoup导入方法跟书中的差异:
# -*- coding: utf-8 -*-
import csv
from bs4 import BeautifulSoup #bs4之后导入的方法与书中的老版本不一样
# Read in unemployment rates
reader = csv.reader(open('unemployment-aug2010.txt', 'r'), delimiter=",") #文件名用数据的名字,如果直接下载,则为unemployment-aug2010.txt
# Load the SVG map
svg = open('counties.svg', 'r').read() #文件名为SVG地图的名字
#SVG里每条路径都有唯一ID,正好是其所属州+所属县,失业数据里也有州和县的代码,不过是分开的。如,阿拉巴马州Autauga县的州码是01,县码是001,在SVG图中路径ID就是01001
unemployment = {}
rates_only = [] # To calculate quartiles
min_value = 100; max_value = 0; past_header = False
for row in reader:
if not past_header:
past_header = True
continue
try:
full_fips = row[1] + row[2] #将州码和县码合成一个数字,在Python规则里数列从第0个开始,[1]代表数列里的第二个数
rate = float( row[5].strip() )
unemployment[full_fips] = rate
rates_only.append(rate)
except:
pass
# Load into Beautiful Soup
soup = BeautifulSoup(svg) #bs4不需要再定义空标签.构造方法的 selfClosingTags 参数已经不再使用.
# Find counties
paths = soup.findAll('path')
# Map colors
colors = ["#F1EEF6", "#D4B9DA", "#C994C7", "#DF65B0", "#DD1C77", "#980043"] # Red-purple
# County style , fill在代码最后,值为空,由各县失业率来定
path_style = 'font-size:12px;fill-rule:nonzero;stroke:#FFFFFF;stroke-opacity:1;stroke-width:0.1;stroke-miterlimit:4;stroke-dasharray:none;stroke-linecap:butt;marker-start:none;stroke-linejoin:bevel;fill:'
# Color the counties based on unemployment rate
for p in paths:
if p['id'] not in ["State_Lines", "separator"]:
# pass
try:
rate = unemployment[p['id']]
except:
continue
# Linear scale
if rate > 10:
color_class = 5
elif rate > 8:
color_class = 4
elif rate > 6:
color_class = 3
elif rate > 4:
color_class = 2
elif rate > 2:
color_class = 1
else:
color_class = 0
color = colors[color_class]
p['style'] = path_style + color
print soup.prettify()
把上面的文件保存在与地图、失业率数据相同的文件夹下,然后在Terminal(Mac)中打开对应的存储路径,再输入:
python colorize_svg.py > us_unemployment_map.svg
怎么样,顺利完成后还是很开心的。SVG可以在illustrator中随意编辑,发挥去吧,少年:)